


The best part of articles like these is when your future self gets to look back in glee as someone does the full critique of your bad/good, before/after comparison with something decidedly even better (and probably more marketable). I understand that the fashionability of Site Reliability Engineering is undeniable. Perhaps this article’s great shame is that it won’t be the provocative takedown of the SRE Workbook’s “high quality postmortem” you might have been yearning for. The truth is every one of its contributors wants to make things better like everyone else, and that effort sincerely deserves to be appreciated.
One of the challenges safety culture has been up against in other industries is grappling with dichotomies like “old view” vs “new view”. It should be easy for us to avoid these schisms because, by and large, the sorts of paradigms we’ve had in software seem comparatively frivolous (e.g., Waterfall/Agile, ITIL/DevOps, Monolith/Microservices) other than the very important fact that computers were definitely, unequivocally a mistake compared to not-computers.
Given that there hasn’t been a canonical “getting started” point for Learning from Incidents in Software, the methods and tools we have available to us are all over the place, and left as an exercise to the reader. This leaves organizations unsure where to invest their efforts, especially since learning from incidents is not fully recognized as a separate area of expertise.
The one thing I do feel confident calling out is that there is no one-size-fits-all approach to learning from incidents. There is no one template, single method, diagram, or model that will ever be wholly and universally effective. The nuances to Learning from Incidents require that organizations take the time to reflect on what does and does not work at their company in the aftermath of an incident.
So rather than pitching a checklist or a maturity model or a program to take your incident reports to the next level, let’s explore the characteristics of post-incident activities that are pushing the envelope in software–many of which arise from the findings in fields like Resilience Engineering and Human Factors.

There’s a lot to expand on any of these points. But if anything here should look like advice, it’s this: don't let an incident review be the end. Make it a springboard, not a superficial, seemingly satisfying facade of closure. The largest responsibility in all of this is to amplify what has been learned. Share the context!
Make incidents a vehicle for insight generation.
“The problem comes when the pressure to fix outweighs the pressure to learn.” –Todd Conklin
I know you’re not supposed to just tell people straight up when a Trojan Horse is a Trojan Horse, but the thing is, incidents are the most effective way to open the door to difficult discussions and ultimately, design improvements.
This diagram from Gary Klein’s “Seeing What Others Don’t” is intriguing!
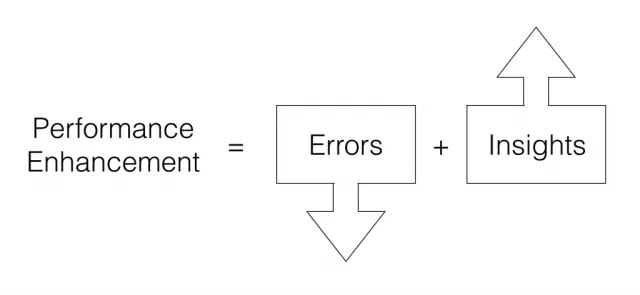
It complements the ‘Safety II’ idea that there’s only so much you can do to prevent things from going wrong through error reduction. Insight generation, however, is theoretically unbounded. The more that we can get people engaged in post-incident activities, the more potential there is for new insight.
To exemplify this notion, Nora Jones recently presented how the journey of designing Chaos Engineering experiments can be more insightful than the outcomes of the experiments themselves (Chaos Engineering Traps talk , Chaos Engineering Traps blog post).
What difference does it make?
The most useful development I find is this kind of work (investing time in learning from incidents) can make even the smallest incidents capable of sparking big conversations.
Particularly notable is that presenting a next-level incident report to teams who haven’t seen anything like it before has a huge advantage. You get the benefit of being able to ask the naive questions without judgment, and to say, “Come along this journey with me.” You get to form a sort of learning team and the rapport you build by doing that is monumental.
An effective report ends up putting all of the context you’ve collected together in front of everyone, with no one particular voice attached to it, and with no overbearing recommendations or opinions. It presents things in the form of “this is what people told us” and “this is what the data showed” rather than taking an active stance or position. It lowers the bar immensely for everyone to feel like they can collaborate on making things better and align on the next direction to take. This is why it is so important to get an impartial, respected, third party to conduct cognitive interviews and formulate the report. If the incident analyst participated in the incident, they will inevitably have a deeper understanding and bias towards the incident that will be impossible to remove in the process of analysis.
How it matters
The cliche idea that we would do this work to reduce the number of incidents or to lessen the time to remediate is too simplistic. Of course organizations want to have fewer incidents, however stating this as an end goal actually hurts our organizations. Indeed, it will lead to a reduction in incident count–not from actually reducing the number of incidents, but rather lessening how and how often they are reported.
“What labeling a fragment of behavior as an error really means is that we do not yet have a good enough understanding of the problem. “Error” counts are thus measures of ignorance, rather than measures of risk.”
- The Error of Counting Errors, Robert L. Wears
The typical quantitative analysis many tend to model incidents with isn’t good enough (e.g., frequency of incidents, duration, impact windows). We also can’t stop when we’ve constructed what we think to be the causes. There are so many problems people are coping with beyond what triggered an incident.
Aspirationally, we do want to avoid catastrophic STKY/STBY events (Stuff That Kills/Bankrupts You), but the sinister thing at play here is the uncertainty that arises with complexity. Making the goal to learn as much as possible about incidents in order to generate insight is what allows us to outmaneuver the complexity that’s coming at us as we continue to be successful, all while minimizing the amount of operational human misery needed to support the system.
So much of the potential leverage is created with storytelling. Stories live beyond the incident. They support learning in perpetuity, provided we share and engage with the stories! The next bit of code someone writes is loaded up with the context of all the gotchas from stories past. This deeply qualitative work allows us to extend our reach beyond the scope of a single incident, to go past fixing its classification of failure, and to learn how to cope more gracefully with new forms of challenges and pathways to failure we haven’t anticipated yet.
Try to see the potential for what’s possible because it’s going to be present in your next incident.
What is described in this article, other industries see as the mere basics of how to kick it up a notch. For software, this is still low hanging fruit and a competitive advantage.
“Getting started” starts now.
References for further Reading & Learning:
Moving past shallow incident data
Learning from the you didn't have
The Theory of Graceful Extensibility
The Three Traps of Accident Investigation